Point-in-polygon Query
A widely used function in GIS and spatial applications is the point-in-polygon query which finds whether a point is inside a polygon or not. Typically, this function is used as a spatial-join predicate to relate a large set of points to a smaller set of polygons, for example, associate a set of geo-tagged tweets to states in the whole world. If the polygons are relatively simple, e.g., a few tens of points per polygon, then we can use any simple spatial join algorithm such as plane-sweep or partition-based spatial merge join (PBSM). However, if the polygons are rather complex, e.g., tens of thousands of points per polygon, then a single point-in-polygon query becomes too expensive and regular solutions do not scale. In this blog post, I'll describe a simple technique that we applied using Pigeon and SpatialHadoop to speed up the point-in-polygon query in the case of very complex polygons.Case Study 1: Mangrove locations in Provinces
This case study was brought into my attention by Prof. Arthur Lembo in Salisbury University and he described it in more details in a blog post. Simply, there is a list of mangrove locations and a list of provinces, and we need to find the province of each mangrove. While the size of the data is not huge (37 million points and 400 polygons), single machine techniques took days to process the data due to the huge complexity of the polygons which increases the processing cost of the point-in-polygon predicate. He tried SpatialHadoop but it didn't help much in this case as the size of the data is too small to make use of indexes and the bottleneck is still in the point-in-polygon query.He contacted me last summer with his concerns that SpatialHadoop was not that useful for the query in hand. I worked out a solution with him which is outlined in this blog post.
Case Study 2: Geotagged tweets in States
For the sake of demonstration, we will use a simple example in this blog post. We have a set of geotagged tweets and we need to associate each tweet with a state or province in the whole world. This requires calling the point-in-polygon query to find the state that contains each tweet. Of course for this simple example, we can simplify the polygons, by reducing its details, to speed up the point-in-polygon query and accept a small degree of error. However, this technique cannot generally apply as some applications require a high degree of accuracy, such as the first case study.First-cut Solution (filter-refine approach)
The first-cut solution that one can think of, is to use a simple filter-refine approach using MBR. Simply, the filter step compares a point to the MBR of the polygon, if it lies inside the MBR, the refine step compares the point to the actual polygon representation. The goal is to avoid the complex point-in-polygon computation if the point is clearly outside of its range. This technique can indeed avoid some complex computation, however, it will perform at least one point-in-polygon in the refine step for each pair in the answer.This approach is already used in two spatial join algorithms implemented in SpatialHadoop, Distributed Join (DJ) and Spatial Join MapReduce (SJMR). The results are as follows:
Using SJMR: 1717.101 seconds
Using DJ: 3247.553 seconds
Notice that the Distributed Join technique performed poorly in this case due to the small input size which does not make full use of the indexes.
Quad-tree Decomposition
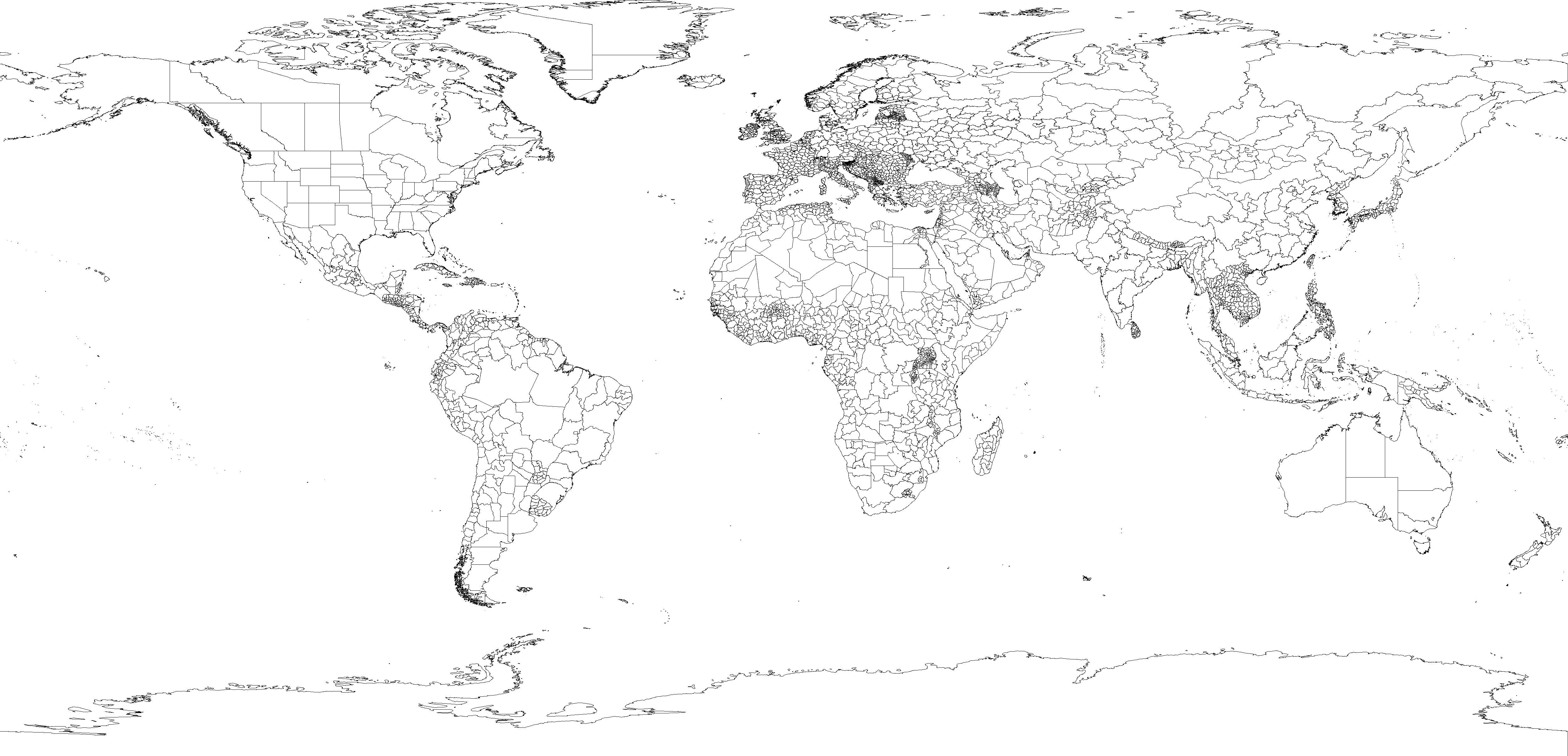 |
| Original input - Click to expand |
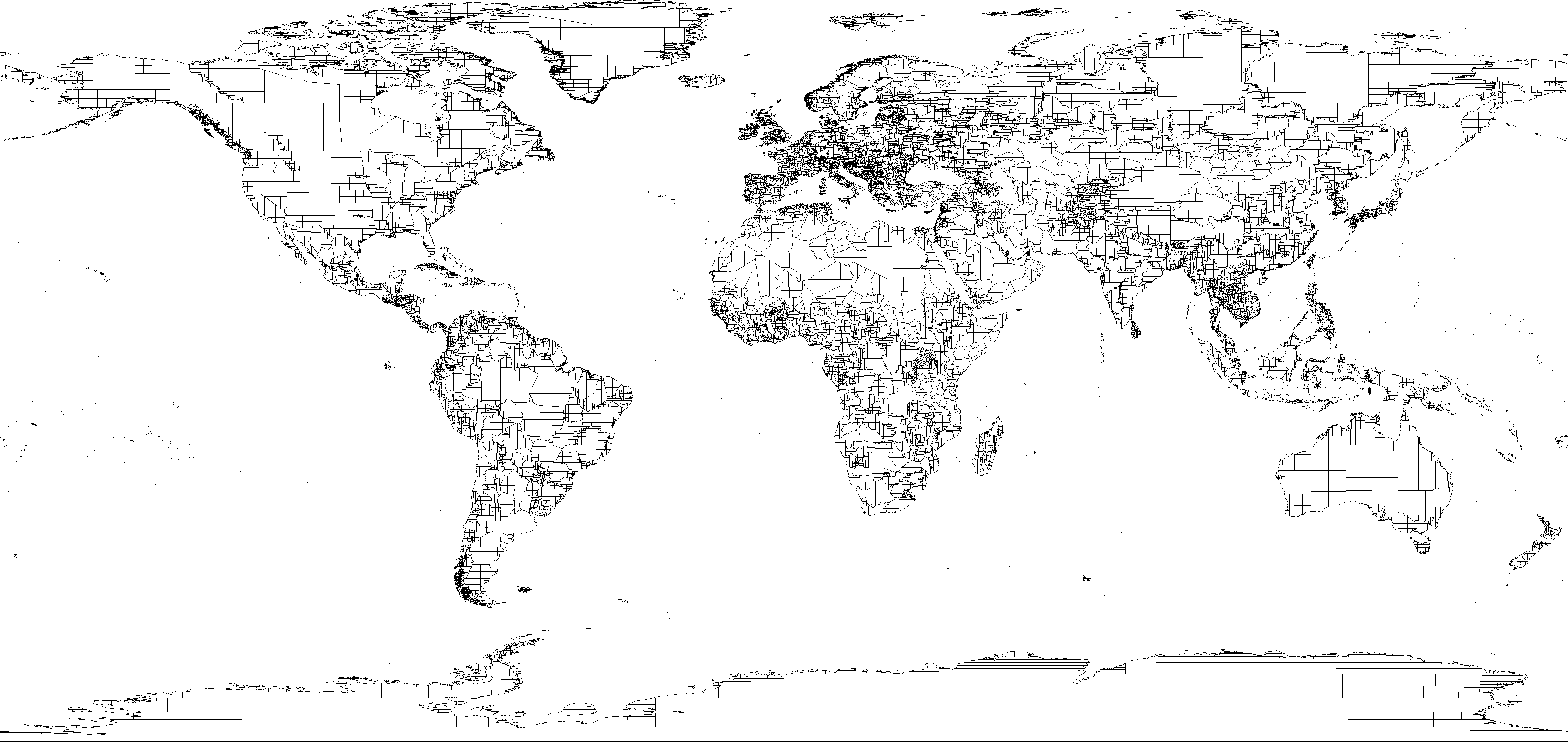 |
| After decomposition - Click to expand |
There are many ways we can decompose a complex polygon into smaller ones. One way is to use a triangulation mechanism which breaks it down into triangles. The method we use in this article is based on Quad-tree where we break a complex polygon recursively into four quadrants based on the MBR of the polygon. We keep breaking a polygon into quadrants until the number of points in each simple polygon is less than a threshold. This threshold allows us to easily control how deep we need to simplify the polygons. Using a smaller value will generate too many simple polygons, while using a larger value will generate too few complex polygons. We used a value of 100 in our experiments but you can try other numbers and watch the performance difference. With this value, the 4,667 input polygons are decomposed into 62,861 smaller polygons.
With this approach, we got impressive results for both SJMR and DJ algorithms as shown below:
SJMR: 374.363 seconds (4.6X speedup)
DJ: 80.113 seconds (40X speedup)
The results shown above are from an Amazon EMR cluster of 1 master node and 9 slave nodes, both of instance type 'm3.xlarge'. Notice that with this approach, DJ approach became much faster than SJMR as the decomposition increased number of polygons which allowed the index to be more useful.
Using the decomposition technique in SpatialHadoop and Pigeon
In this part we will describe how to apply the above technique using SpatialHadoop and Pigeon. We could not make the above datasets available for public due to legal reasons, however, you can find many points and polygons datasets in the SpatialHadoop datasets page. The source code of SJMR and DJ are both available as part of SpatialHadoop. The source code of the Quad-tree decomposition function is available in Pigeon.The following Pigeon script is used to compute the decomposition of a dataset.
--------------------- Decompose.pig ----------------------
REGISTER pigeon-0.2.1.jar;
REGISTER jts-1.8.jar;
REGISTER esri-geometry-api-1.2.jar;
IMPORT 'pigeon_import.pig';
polys = LOAD '$input' Using PigStorage() AS (geom1);
polys = FOREACH polys GENERATE FLATTEN(ST_Decompose(geom1, 100)) AS geom1;
polys = FOREACH polys GENERATE ST_AsText(geom1);
STORE polys INTO '$output';
--------------------- End of script ----------------------
To use this script to decompose the 'world_states' files into 'world_states_simple':
pig -p input=world_states -p output=world_states_simple Decompose.pig
To run SJMR on the world_states and tweets files:
> shadoop sjmr world_states tweets shape:wkt
Similarly, you can run on the decomposed version 'world_states_simple':
> shadoop sjmr world_states_simple tweets shape:wkt
To run the DJ algorithm, you need to first index the input files using these commands (one for each file):
> shadoop index -D dfs.blocks.size=16777216 world_states world_states.r+tree sindex:r+tree shape:wkt
> shadoop index -D dfs.blocks.size=16777216 world_states_simple world_states_simple.r+tree sindex:r+tree shape:wkt
>shadoop index -D dfs.blocks.size=16777216 tweets tweets.r+tree sindex:r+tree shape:wkt
We adjust the index block size to 16MB as the input files are very small and we needed to partition it across more machines.
Finally, to run the DJ algorithm:
> shadoop dj world_states.r+tree tweets.r+tree -no-output shape:wkt
> shadoop dj world_states_simple.r+tree tweets.r+tree -no-output shape:wkt
The current implementation of SJMR and DJ require the two input datasets to be of the same file format. However, the algorithm can conceptually run on two different dataset formats.
Acknowledgement
The experiments were run on Amazon Web Services (AWS) and were supported by AWS in Education Grant award.External Links
- SpatialHadoop website http://spatialhadoop.cs.umn.edu/
- Ahmed Eldawy and Mohamed F. Mokbel, "SpatialHadoop: A MapReduce framework for Spatial Data", ICDE 2015, Seoul, South Korea, April, 2015
- Natural Earth Data
http://www.naturalearthdata.com - Suprio Ray, Bogdan Simion, Angela Demke Brown, Ryan Johnson: "Skew-Resistant Parallel In-memory Spatial Join". SSDBM 2014: 6:1-6:12
website design west palm beach fl should be updated with the latest in coding and browser compatibility updates.
ReplyDeleteI like reading your blog
ReplyDeletewez-pozyczke